Chapter 2 Data sources
We are using two datasets for our project. The first one is an inspection results data, where we downloaded the dataset from the official website.
The second dataset is restaurant review dataset during last restaurant week. We scraped this dataset from Opentable using rvest. We first get the name of restaurants participating in the NYC restaurant week.
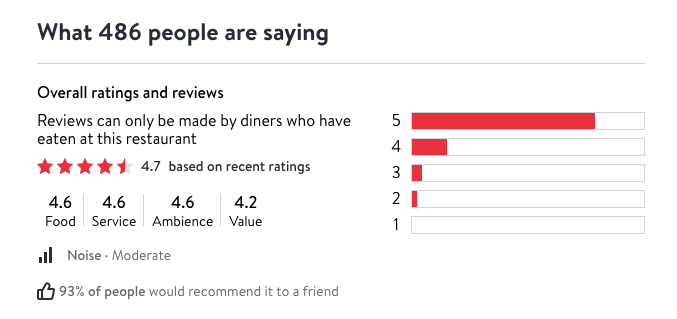
 Then we use the name we got to scrape detailed information that we need. The scraped data contains 9 columns: food_review, ambience_review value_review, service_review, price_range review_count, average_review, restaurant_main_type. The detailed information like review scores are scraped from the restaurant page.
Then we use the name we got to scrape detailed information that we need. The scraped data contains 9 columns: food_review, ambience_review value_review, service_review, price_range review_count, average_review, restaurant_main_type. The detailed information like review scores are scraped from the restaurant page.

The way we scraped data was that we restrict the region into Manhattan area so that most restaurants will appear in the health inspection data. Since there are 3 pages of restaurants, we used url to do page indexing. Then we constructed a loop with page numbers. In side this loop we have a nested loop that use the restaurant names we got froim this page to modify the url. We did some regex on the names so that they can fit the way opentable use them. For each column we append each value into a list. After we finish the nested loop, we will combine all the lists we have into our final dataset. Following is the code for our scaping script:
There is not scraping process for our inspection data. The data contains grade, score, date of the inspection, violation description and the restaurant name. Our further task is to join these two datasets, and explore some interesting relationship between these two.